1. 공식 소스
재무제표는 OpenDART/DART, 시장자료는 KRX, 거시지표는 ECOS/KOSIS로 매핑합니다.
이 Evidence 페이지는 포트폴리오 프로젝트의 데이터 검증 설계를 설명하는 참고용 문서입니다. 특정 기업, 증권, 대출, 신용등급, 투자 판단에 대한 권고나 보증이 아닙니다.
여기에 제시된 데이터 소스·문헌·검증 절차를 실제 업무에 적용할 경우, 원천 데이터의 최신성·정확성·법적 사용 가능성을 별도로 확인해야 합니다. 이 페이지를 근거로 발생하는 손실, 분쟁, 법적 문제 등에 대해 제작자는 법령상 허용되는 범위 내에서 책임을 지지 않습니다.
Data evidence · interview defense
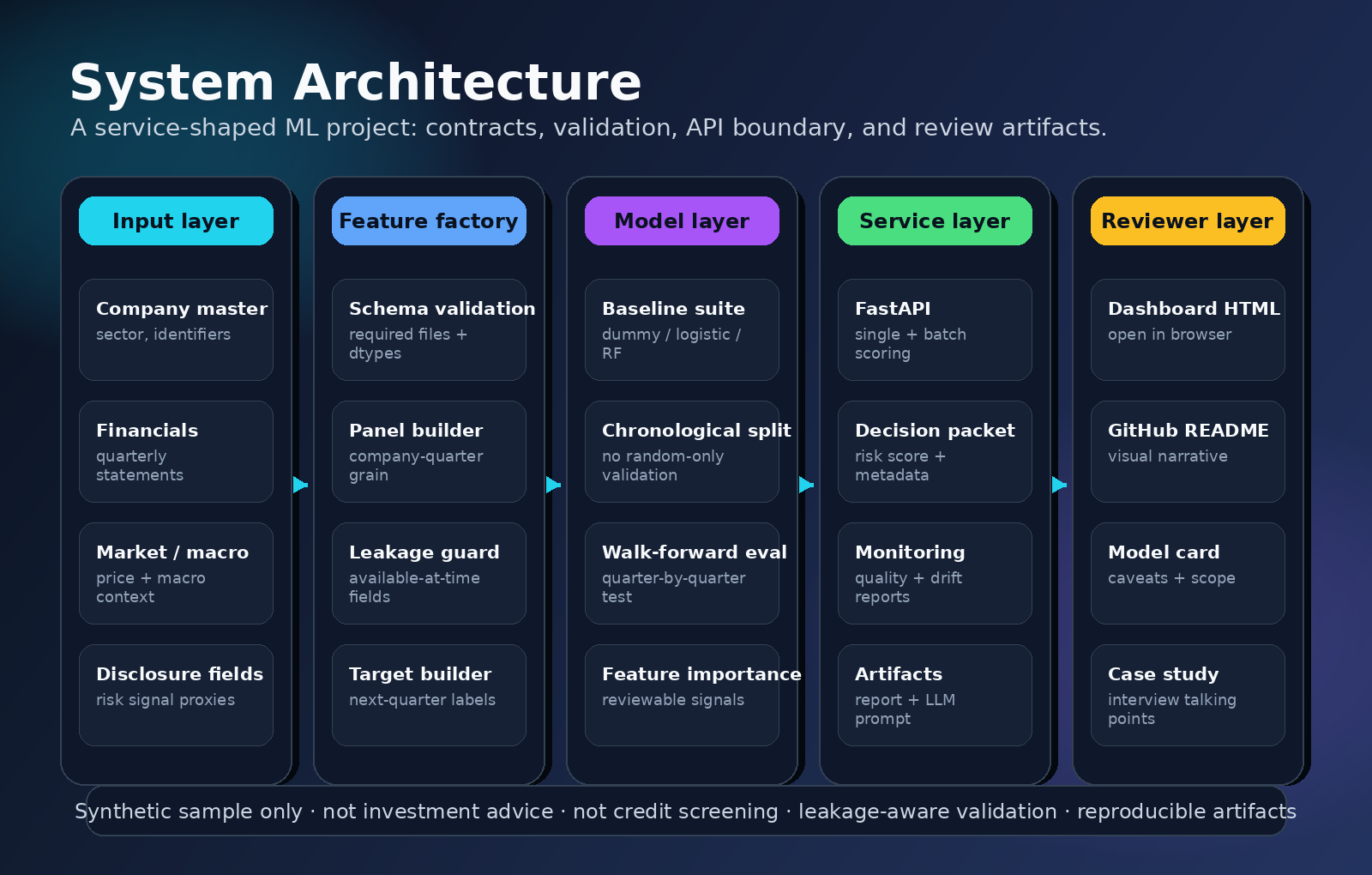
이 페이지는 포트폴리오 리뷰에서 나오는 데이터 출처, 과거자료 검증, 논문 근거 질문에 답하기 위한 evidence pack입니다. 현재 데모는 synthetic이지만, 실데이터 확장 시 어떤 공식 자료와 어떤 검증 절차를 쓰는지 명확히 보여줍니다.
No investment advice. This is a validation-design note for a portfolio project.
재무제표는 OpenDART/DART, 시장자료는 KRX, 거시지표는 ECOS/KOSIS로 매핑합니다.
공시일과 예측일을 분리하고, available_date <= prediction_date 조건으로 미래정보 누수를 막습니다.
Altman, Ohlson, Fama-French, Bharath-Shumway 흐름을 참고해 ratio/logit/baseline 비교를 둡니다.
Source mapping
아래 매핑은 “현재 demo data”가 아니라 “실데이터 확장 시 검증 가능한 기준 소스”입니다.
| Input | Official source | Why it is defensible | Project file |
|---|---|---|---|
| 재무제표 | OpenDART / DART | 상장사 정기보고서 기반 재무정보 API와 기업공시 저장소 | financial_statement_quarterly.csv |
| 공시 이벤트 | DART reports | 분기·반기·사업보고서 및 주요사항보고서 기반 이벤트 추출 | disclosure_features_quarterly.csv |
| 시장자료 | KRX Data Marketplace / Open API | 거래소 시장정보, 가격, 거래량, 통계 데이터 | market_quarterly.csv |
| 거시경제 | BOK ECOS / KOSIS | 중앙은행 및 국가통계포털의 공개 통계 API | macro_quarterly.csv |
| 전자공시 포맷 | XBRL | business reporting을 위한 표준화된 데이터 교환 방식 | schema / account mapping |
Literature anchors
재무비율을 이용한 기업 부실/파산 예측의 고전 baseline입니다. 수익성, 유동성, 레버리지 계열 feature를 쓰는 이유를 설명할 수 있습니다.
재무비율 기반의 probabilistic/logit bankruptcy prediction 흐름입니다. risk score를 확률/점수로 내는 방식의 근거가 됩니다.
시장, 규모, book-to-market 등 공통 위험요인 문헌입니다. 시장자료와 재무자료를 함께 보는 근거로 사용합니다.
default prediction에서 복잡한 모델과 단순 baseline의 out-of-sample 비교가 중요하다는 점을 보여줍니다.
Validation protocol
Interview answer
20초 버전
데이터 근거는 OpenDART/DART, KRX, ECOS/KOSIS 같은 공식 공개 데이터로 잡고 있습니다.
모델 근거는 Altman, Ohlson 같은 financial distress 문헌과 시장위험요인 문헌을 baseline으로 삼습니다.
중요한 건 random split이 아니라 공시일 기준 point-in-time backtest로 미래 정보 누수를 막는 것입니다.
현재 데모는 synthetic이라 실제 성능 주장은 아니고, 실데이터 검증 설계를 보여주는 포트폴리오입니다.1분 버전
현재 공개 데모는 synthetic data를 사용하지만, 실데이터 확장 시 재무제표는 OpenDART/DART,
시장자료는 KRX, 거시지표는 ECOS/KOSIS에서 가져오도록 설계했습니다.
입력 데이터는 schema validation으로 타입과 범위를 검증하고, report date와 prediction date를 분리해
미래 공시 정보가 feature에 섞이지 않도록 합니다.
방법론적으로는 Altman Z-score나 Ohlson O-score 같은 financial distress baseline을 두고,
ML 모델은 walk-forward validation으로 baseline 대비 성능과 calibration을 확인합니다.References