0.125M
LiteRaceSegNet estimated trainable parameters
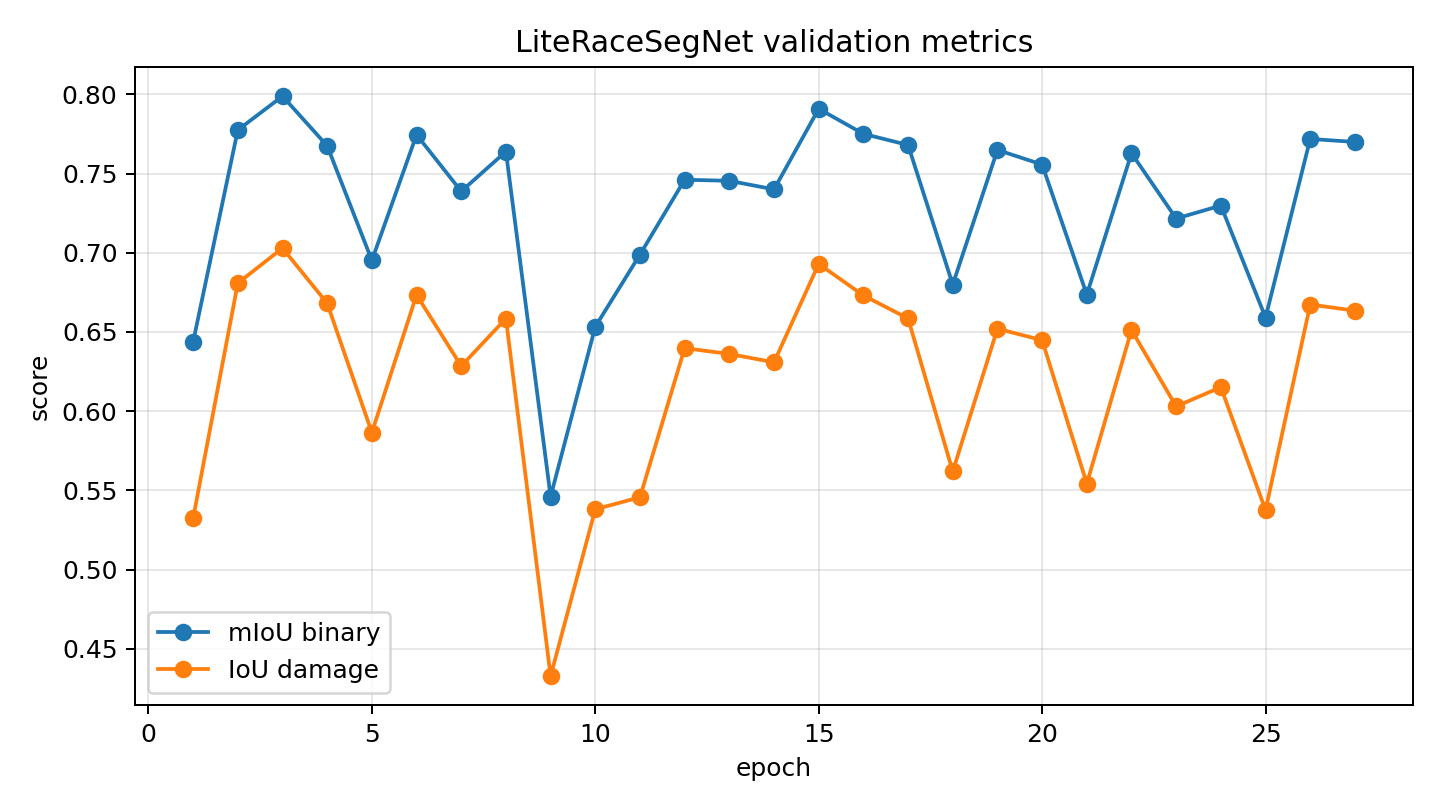
0.799
Best validation binary mIoU from saved evidence
13.8M
HoshiLM-M expected scale with vocab≈8k
Segmentation evidence

Training metrics
Architecture
LiteRaceSegNet
Input road image → MobileNetV3-style lightweight backbone → Context branch + Boundary-aware branch → Fusion → Damage mask
작은 손상 영역과 불규칙한 경계를 겨냥한 경량 segmentation pipeline.
HoshiLM-KR
Tokens → Token/Position Embedding → Decoder Block × N → LayerNorm → LM Head → Next-token prediction
대형 상용 언어모델급 모델이 아니라, decoder-only Transformer 학습 구조를 재현하기 위한 소형 연구/교육용 구현.